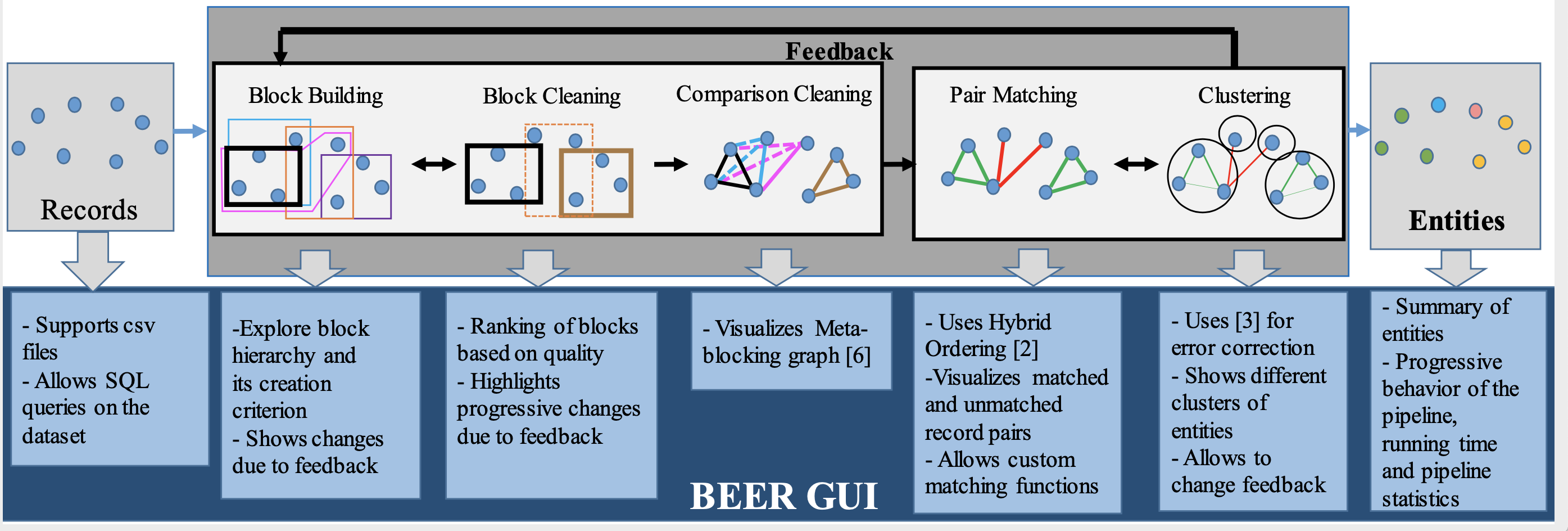
What is BEER?
Blocking is a key component of Entity Resolution (ER) that aims to improve efficiency by quickly pruning out non-matching record pairs. However, depending on the noise in the dataset and the distribution of entity cluster sizes, existing techniques can be either (a) too aggressive, such that they help scale but can adversely affect the ER effectiveness, or (b) too permissive, potentially harming ER efficiency. We propose a new methodology of progressive blocking that enables both efficient and effective ER and works across different entity cluster size distributions without manual fine tuning.
System Architecture